kuniga.me > NP-Incompleteness > [Paper] Resilient Distributed Datasets
[Paper] Resilient Distributed Datasets
17 Jun 2022
In this post we’ll discuss the paper Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing by Zaharia et al [1]. In a nutshell, Resilient Distributed Datasets (RDDs for short) is the main abstraction used by the Spark query engine.
Resilient Distributed Datasets
Partitions
RDD is a read-only, collection of records grouped in partitions. It can represent data in storage (such as HDFS) but also the result of transformations (such as map, filter and joins) of other RDDs.
Users can control how RDDs are partitioned via a partitioner.
Lineage Graph
RDDs are lazily evaluated. It can be derived from other RDDs by storing this information via a lineage graph.
Storing the lineage is also useful for recovery. For example, if one of the partitions of a RDD fails, it can be use its lineage graph to recompute only the partition that failed.
A child node might depend on multiple parent nodes, for example through a union of multiple RDDs. Conversely a node might be a dependency of multiple children. If a node is a dependency of a single child node, we call it a narrow dependency, otherwise we call it a wide dependency. Figure 1 shows some examples.
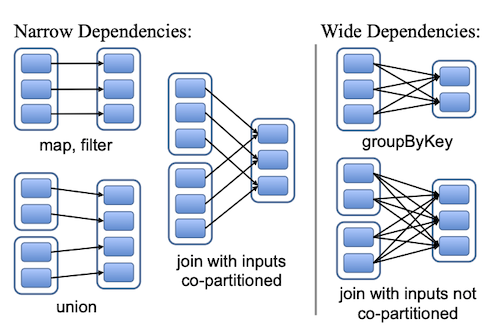
A narrow dependency is desirable for optimization because the parent node can then be potentially co-located with the child, we’ll see in more details in Scheduling.
Persistence
Users can indicate that a RDD is kept in memory. It can then be shared between multiple downstream RDDs to speed up computation. If the data is too big for memory it might instead be persisted in disk.
Scala API
The Spark framework provides a Scala API used to manipulate RDDs. For example, if we want to read from HDFS and filter lines starting with ERROR, we can do:
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()Behind the scenes, a RDD is created for lines. When persist() is called, it tells the RDD to be kept in memory, indicating it will be used later. So far, no work has been done, only the computation graph is being constructed.
Next, we can call count(), which will cause the computation to be evaluated and returned to the local machine.
errors.count()We can then do further processing on errors. The example below filters lines containing HDFS, retrieves the 4-th column and returns the list to the user, forcing another evaluation.
errors.filter(_.contains("HDFS"))
.map(_.split('\t')(3))
.collect()Since errors is cached in memory (due to .persist()), we won’t be reading data from HDFS again.
Implementation Details
A RDD is represented by a class implementing an interface, with the following core methods [1]:
| Operation | Meaning |
|---|---|
partitions() |
Return a list of Partition objects |
preferredLocations(p) |
List nodes where partition p can be accessed faster due to data locality |
dependencies() |
Return a list of the parents |
iterator(p, ppIt) |
Compute the elements of partition p given iterators for its parent partitions ppIt |
partitioner() |
Return metadata specifying whether the RDD is hash/range partitioned |
Some examples make it easier to understand.
HDFS Files
For the RDD representing HDFS files:
partitions()returns one partition for each HDFS block of the filepreferredLocations(p)returns the nodes where the HDFS block is oniterator(p)read the data for the HDFS block
map()
Applying the map(f: T -> U) function over a RDD (the parent) creates another RDD:
partitions()same as parentpreferredLocations(p)same as parentdependencies()contains a reference to the parentiterator(p, ppIt)applies the mapping functionfover each element of the parent partitionppItto generate the elements ofp.
join()
The join operation is only allowed between RDDs whose internal type is a pair of key-value and it does the join based on matching keys.
Let’s consider a simple example: joining between two datasets keyed on some ID, supposing both datasets are partitioned the same way by ID. The joined RDD can inherit the partition scheme (the partitioner) from either parent, so its partitions will also be based on the ID column.
A more complex case is if the parent datasets are not partitioned the same way, in which case the resulting RDD has to pick one of the parent’s partitioner or come up with its own.
partitions()dependsdependencies()contains a reference to both parentsiterator(p, ppIt)combines pairs of key-value from the parents with the same key into one pairpartitioner()depends
Scheduling
Once we execute one of the “evaluation” functions like count(), the scheduler will construct a DAG of stages to execute based on the lineage graph of the RDD.
It tries to co-locate the narrow dependencies together and for the wide dependencies it performs shuffling like in MapReduce [2]. For shuffling, it persists the parents’ partitions to disk to make fault recovery simpler.
It also takes into account cached data, if tries to colocate computation in the node that holds the cache data. Otherwise the scheduler will leverage the preferredLocations() from the RDDs.
Figure 2 shows an example of the arrangement of stages for a given Spark job.
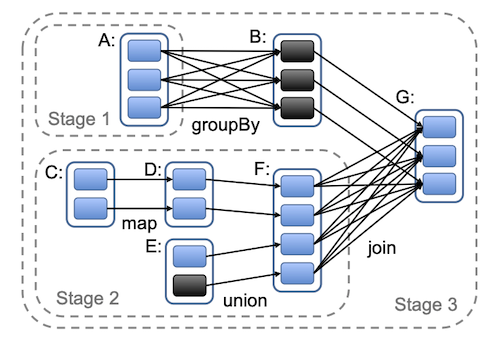
If a node fails, it will recompute the work in another node. In case the parent’s data is not persisted, it will recompute the dependencies.
Comparison with FlumeJava
I find it appropriate to compare RDD/Spark and FlumeJava, considering we discussed the latter in a recent post.
| Topic | FlumeJava | Spark |
|---|---|---|
| API Language | Java | Scala |
| Unit of abstraction | MSCR | RDD |
| Evaluation | Explicit via .run() |
Implicit via calls like .count() |
| Underlying Framework | MapReduce | Mesos |
| Recovery Mechanism | Checkpoint (between MapReduce jobs) | Mix of checkpoint, cache and recomputation |
| Cache | Disk (distributed filesystem) | Memory/Disk |
| Optimization | ParallelDo Fusion, Sink Flattening | Narrow Dependency Co-location |
Conclusion
Spark’s architecture is, surprisingly, relatively simple! I don’t recall where I heard this but it was something along the lines “In distributed systems, simple is better”. This is obviously applicable to software in general, but distributed systems have inherent complexity so that the tradeoff between simplicity vs. say, efficiency, is different than in a single node.
I also found RDDs similar to FlumeJava in many aspects. The major gains enabled by RDDs seems to be from opening the MapReduce black box for a tighter integration with the overall system.
