kuniga.me > NP-Incompleteness > Revisiting Python: Modules
Revisiting Python: Modules
24 Dec 2021
This is a post in the series on revisiting Python. I’ve been using Python for a long time but most of my learning has been organic and on-demand. By actively studying its parts we might learn to do things in better way, or help us understand why our code does not work the way we would expect in corner cases.
In the previous post we talked about Object Oriented Programming, and in this we’ll discuss the modules system.
This was been tested with Python 3.9 (this post might receive updates when newer versions make it obsolete).
The Module Object
A module has a 1:1 mapping to a file, as described in [1]:
A module is a file containing Python definitions and statements. The file name is the module name with the suffix .py appended.
There’s an exception to this rule which we’ll see later.
When we import a module with import, it adds an object of the built-in class module to the current scope:
import math
print(type(math)) # <class 'module'>Module Type
I don’t know if this distinction is used in any official documentation but to me it’s helpful to categorize a module into:
- built-in - part of the interpreter. Example:
sys - library - a system-level library (corresponding to
.sofiles on Linux/Mac). Example:math - file - regular Python file. Example:
inspect - package - corresponds to a directory, and can be divided into namespace and regular (see Packages). Example:
importlib
They’re all abstracted behind a module but we can see they return different things for inspect.getfile():
import sys
import math
import inspect
import importlib
# built-in
# TypeError: <module 'sys' (built-in)> is a built-in module
print(inspect.getfile(sys))
# library
# '/usr/local/.../python3.9/lib-dynload/math.cpython-39-darwin.so'
print(inspect.getfile(math))
# file
# '/usr/local/.../python3.9/inspect.py'
print(inspect.getfile(inspect))
# package
# '/usr/local/.../python3.9/importlib/__init__.py'
print(inspect.getfile(importlib))Module Name
The module object has the property __name__, that matches the module name. Note that if we alias the module on importing __name__ contains the original name, for example:
import math as new_math
print(new_math.__name__) # mathThere is also a built-in variable, __name__, that is the name that corresponds to the module name where it lives, for example, if we have a file called lib.py:
print(__name__) # libWhen we run the file using python, the variable __name__ is overridden to "main", which is leveraged in a common technique to gate code to only run when called as the entry point file. For example, if we have app.py:
if __name__ == 'main':
print('entry point')The message will only be printed if we executed it as python app.py, but will not if it’s included as a module in some other file.
Import Cache
A module is only imported once, which means that the file corresponding to that module is only executed one time. The modules are cached in the sys.modules variable.
This means it’s possible to hijack that variable to stub a module. Suppose in lib.py we have:
import math
def f():
return math.sin(1)And that we have a custom math_mock.py module:
def sin(x):
return 0.55Then in main.py we can replace the 'math' module:
import math_mock
import sys
sys.modules['math'] = math_mock
# it's important we set sys.modules before this
import lib
print(lib.f()) # 0.55This can be used for example to mock an entire module during tests.
‘This’ Module
Combining the knowledge from the two previous sections, it’s possible to access the module object of the current file via [2]:
import sys
this_module = sys.modules[__name__]Inspecting Modules
In [1] it states:
Each module has its own private symbol table, which is used as the global symbol table by all functions defined in the module
We can see the list of variables defined in a given module using the dir() function:
import math
print(dir(math))
"""[
'__doc__',
'__file__',
'__loader__',
'__name__',
'__package__',
'__spec__',
'acos',
'acosh',
...
]"""Note that this only returns the names. If we’re also interested in the instances corresponding to the names, we can use inspect.getmembers(), which returns a list of tuples (name, instance):
import math
print(inspect.getmembers(math))It’s worth noting that both dir() and inspect.getmembers() are APIs that work with any class instance, and are not specific to modules.
For completion, it’s worth noticing modules also have the __dict__ attribute, which contains a dictionary of name -> instance:
import math
print(math.__dict__)For modules x.__dict__ seems to be equivalent to inspect.getmembers(x) but in general this is not always true [3, 4].
Flavors of Import
There are a few different ways of importing a module and they might have different semantics.
Import Module Object
Let’s consider the syntax used so far:
import mathAs we said before, this adds the math object to the current scope, which really is a reference to a structure in memory. This means we can modify the module contents in runtime, for example, we could override math.sin:
import math
def custom_sin(x):
return 0.0
math.sin = custom_sin
print(math.sin(0.3)) # 0.0Not only will calls to math.sin() use the new implementation, code in other modules using math.sin will also be affected. For example, if we have in lib.py:
def f():
print(math.sin(0.5))And then in main.py:
import math
import lib
def custom_sin(x):
return 0.0
math.sin = custom_sin
print(lib.f()) # 0.0Needless to say this can lead to very confusing behavior. It could be interesting for mocking in tests though.
Import Module Parts
Another syntax for importing is via:
from math import sinThis is more or less equivalent to:
import math
sin = math.sinNote that if you override the implementation of sin, it simply updates the memory the variable sin points to, and not the object math in any way. So if main.py is:
from math import sin
import math
def custom_sin(x):
return 0.0
sin = custom_sin
print(sin(0.3)) # 0.0
print(math.sin(0.3)) # .29552020666Note that math.sin() wasn’t affected.
Import All
We can import all definitions from a module with this syntax:
import * from math
# imported from math
sin(1)This is convenient but it can also become problematic for more complex codebases, for example, if the same name is defined in multiple modules.
Import From Strings
We can import a module from a string via the importlib.import_module function:
import importlib
lib = importlib.import_module('lib')
print(lib) # <module 'lib' from ...We’ll see an use case for this in Lazy Loading Modules below.
Searching for modules
When deciding which directory to search for a file corresponding to a module, the modules loader will look for a list of paths in order. This list can be obtained via:
import sys
sys.pathThis itself is initialized from the environment variable PYTHONPATH. When we run Python via a python file.py, the first entry of sys.path is the directory of file.py, which allows for local imports without further setup, for example when we import lib.py in main.py like above:
import libNote that the modules loader will not search the directory recursively, so if we have foo.py in this structure:
/
| main.py
| sub_dir/
| foo.pyThen importing with in main.py like:
import fooWill not work. We’ll cover subdirectories in the next section.
Packages
A package is a collection of modules like in [1]. It’s roughly a 1:1 map to a directory. It can be divided into regular and namespace packages.
Continuing from the prior example, the correct way to import a file under a directory sub_dir is via:
import sub_dir.foo
print(sub_dir.foo) # <module 'sub_dir.foo' ..In this case sub_dir is considered a package since it contains all the modules corresponding to files under its directory.
Note that the . replaces the / and that this works with multiple depths. For example to import sub_dir/another_dir/bar.py we do:
import sub_dir.another_dir.bar
print(sub_dir.another_dir.bar) # <module 'sub_dir.another_dir.bar'...This causes the name of the imported module to be quite long, so we can use the from ... import syntax:
from sub_dir.another_dir import bar
print(bar) # <module 'sub_dir.another_dir.bar' ...We can import the subdirectory-only instead of its module, for example:
import sub_dir
print(sub_dir) # <module 'sub_dir' (namespace)>
print(sub_dir.foo) # <module 'sub_dir.foo' ..As we see in the output, this is considered a namespace module/package [5], which means it doesn’t have an associated file.
Regular Packages
Before Python 3.3 it used to be necessary to include a file __init__.py for files in subdirectories to be “visible”. It’s still possible to do so. For example, we could have the following structure:
/
| main.py
| sub_dir/
| __init__.py
| foo.pyThe code in __init__.py is executed when it or any of its subdirectories are imported. Suppose it has:
import math
print('i am sub_dir')
a = math.sin(1)If we import it in main.py:
import sub_dir # executes code in sub_dir/__init__.py
print(sub_dir) # <module 'sub_dir' ...Note that sub_dir is not a namespace module anymore since it’s tied to sub_dir/__init__.py, but rather a regular one. Further, the variables in the scope of __init__.py are available for importing:
from sub_dir import math, aImport All Modules!
As in the case with a single module, we can use the * syntax:
import * from sub_dirThe behavior will depend on whether sub_dir has a backing __init__.py or not. If it does, only the variables in the scope of __init__.py will be imported.
The package owner can explicitly control what gets imported when doing the * import by defining the variable __all__ in __init__.py:
__all__ = ["baz"]Now, when we do in main.py:
import * from sub_dirWe’ll see only the module baz has been imported even if other variables were defined in __init__.py. If a __init__.py is missing, nothing is imported.
Intra-package Imports
We can use a relative import syntax within a package. Suppose we have this structure
/
| main.py
| lib.py
| sub_dir/
| another_dir/
| bar.py
| baz.py
| foo.pyIn bar.py we can import module relative to the package sub_dir:
from .bar import f
from ..foo import gNote that only the syntax from <module> import <def> is allowed in this case. The number of dots represent the number of steps up in the file tree take, starting from 0.
We can’t import modules outside the package, so for example, if we had this in bar.py:
from ...lib import fIt would fail, because lib.py is not in the package sub_dir.
Performance
When we run python main.py, all its dependencies are recursively imported and their top level code are executed. For example, consider a file lib.py:
a = very_expensive_function()
def my_func():
print(a)When we include it in main.py:
from lib import my_func
if rare_event():
my_func()Note that very_expensive_function() will be executed even if we rarely or never use my_func() in main(). In an ideal world the author of lib.py should not execute expensive code in the top level but this is hard to control.
This can lead to pretty high start up times for scripts and CLI tools which is a common use case for Python. One option is to lazy load these modules as we’ll see next.
Inlining Imports
The most straightforward way to avoid overhead is by inlining the import as needed, so our main.py would look like:
if rare_event():
from lib import my_func
my_func()which addresses the issue. Recall that module loader only imports modules once so having to inline the import is safe:
if rare_event():
from lib import my_func
my_func()
if another_rare_event()
from lib import my_func
my_func()In the example above, even if both conditions end up returning true, we’ll only execute the code of lib.py once. One major downside of this approach is having to add the import statement in multiple places which can be tedious and error prone.
We now consider an option with lighter syntax.
Lazy Loading Modules
We can use importlib.util to define a function that takes the name of a module as a string and returns a module whose file won’t execute until one of its members is accessed. [6] provides the following implementation (which I’m surprised it’s not part of the API):
import importlib.util
def lazy_import(name):
spec = importlib.util.find_spec(name)
loader = importlib.util.LazyLoader(spec.loader)
spec.loader = loader
module = importlib.util.module_from_spec(spec)
sys.modules[name] = module
loader.exec_module(module)
return moduleWhich we can then use as:
lib = lazy_import('lib')
if rare_event():
lib.my_func()The downside of this approach is that we need to load the module name via string which might make static checkers unable to check whether the module actually exists or catch issues during file renaming, etc.
The documentation in [6] suggests using lazy loaded modules only when strictly necessary:
For projects where startup time is critical, this class allows for potentially minimizing the cost of loading a module if it is never used. For projects where startup time is not essential then use of this class is heavily discouraged due to error messages created during loading being postponed and thus occurring out of context
How do we know which modules to lazy load? We’ll see next.
Detecting Expensive Modules
We can determine which module is taking the most time to import by running our binary with the -X importtime flag. As an experiment, I tried profiling a recent project I worked with t-digest:
make env
./env/bin/python -X importtime tdigest/tdigest.pyIt prints a tree-like structure as text, which is a bit hard to make sense of. Fortunately there are UI tools to better visualize this trace, for example tuna:
pip install tunaWe can save the output of the profiler to a file and visualize it in the browser:
make env
./env/bin/python -X importtime tdigest/tdigest.py 2> /tmp/import.log
tuna /tmp/import.logThe result is in Figure 1.
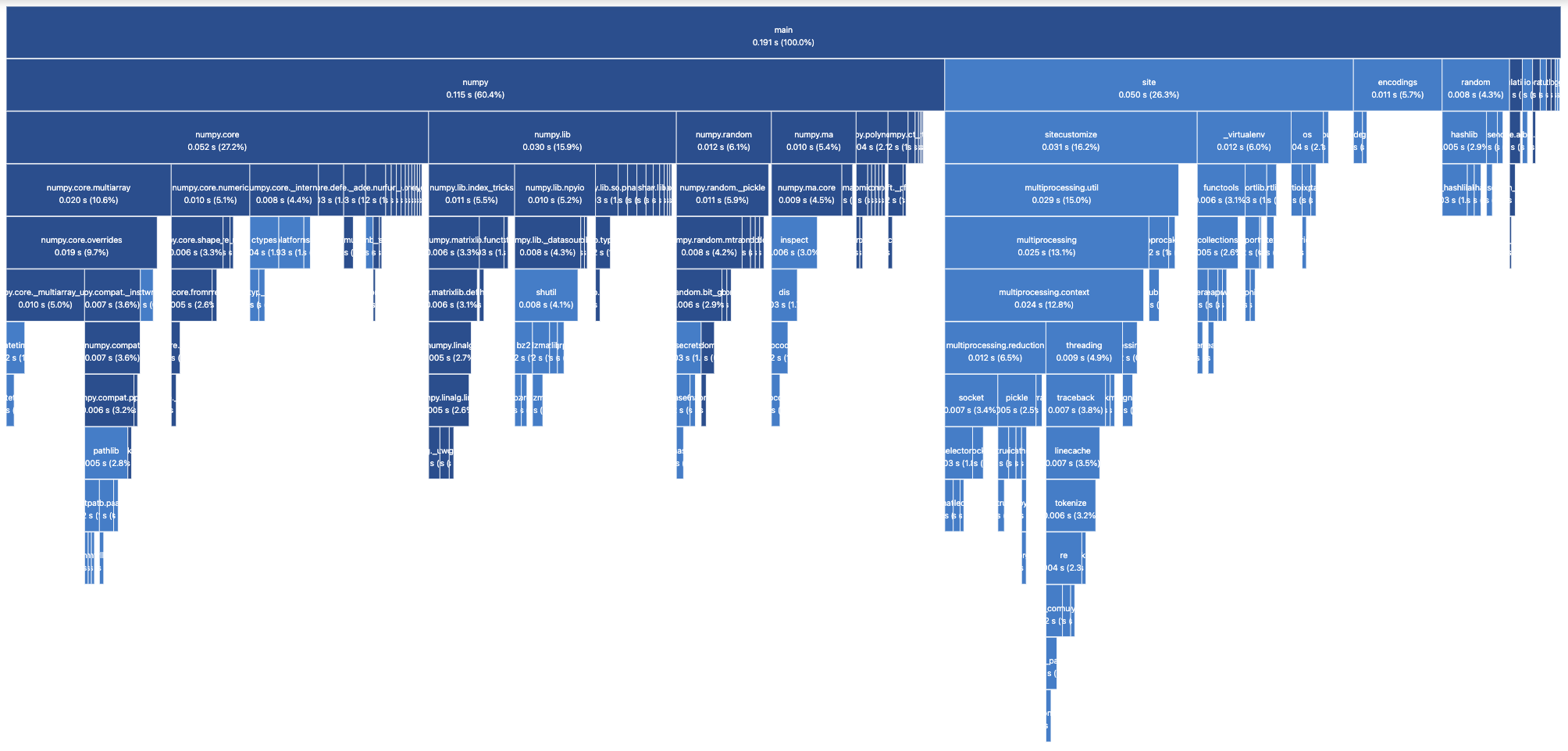
Conclusion
As always, focusing in learning one topic and setting time aside to play around led me to learn many new things. Some of them like the “self module” don’t seem immediately useful but knowing they exist could be handy in the future.
References
- [1] The Python Tutorial: Modules
- [2] StackOverflow: How to get a reference to current module’s attributes in Python
- [3] StackOverflow: What’s the biggest difference between dir() and dict in Python
- [4] StackOverflow: inspect.getmembers() vs dict.items() vs dir()
- [5] The Python Language Reference: The import system
- [6] importlib — The implementation of import
- [7] Command line and environment
